Dende
[Data Scientist] 상관관계 분석 본문
■ .corr을 사용하여 두 열 간의 상관 관계 얻기
다음의 설문조사 데이터가 있습니다. 총 139문항으로 이루어져 있고 해당 카테고리에 대한 선호도를 리커트 5점척도로 나타내고 있습니다.

각 항목들의 다른 항목에 대한 상관관계를 나타내고자 합니다.
df = pd.read_csv('data/young_survey.csv')
df.corr()
하지만 전체의 상관관계는 아무런 소용이 없는 데이터입니다.
인사이트를 발휘해서 좀 더 유의미한 상관관계를 찾아봅시다.
1. 두 항목에 대한 상관관계
df[['Branded clothing','Spending on looks']].corr()브랜드 의류를 좋아하는 사람(Branded clothing)과 외모 꾸미기(Spending on looks) 간의 상관관계를 도출

0.418399 로 뚜렷한 양적 상관관계를 나타내고 있다.
2. 히트맵을 통한 전체 상관관계 시각화
이번에는 사람들의 각 항목에 대한 관심도가 어떤 상관관계를 가지는지 시각화해봅시다.
우선 관심도는 'History' 부터 'Pets'까지 적용이 됩니다.
인덱싱부터 해봅시다.
interest = df.loc[:,'History':'Pets']
interest.head()
interest.corr()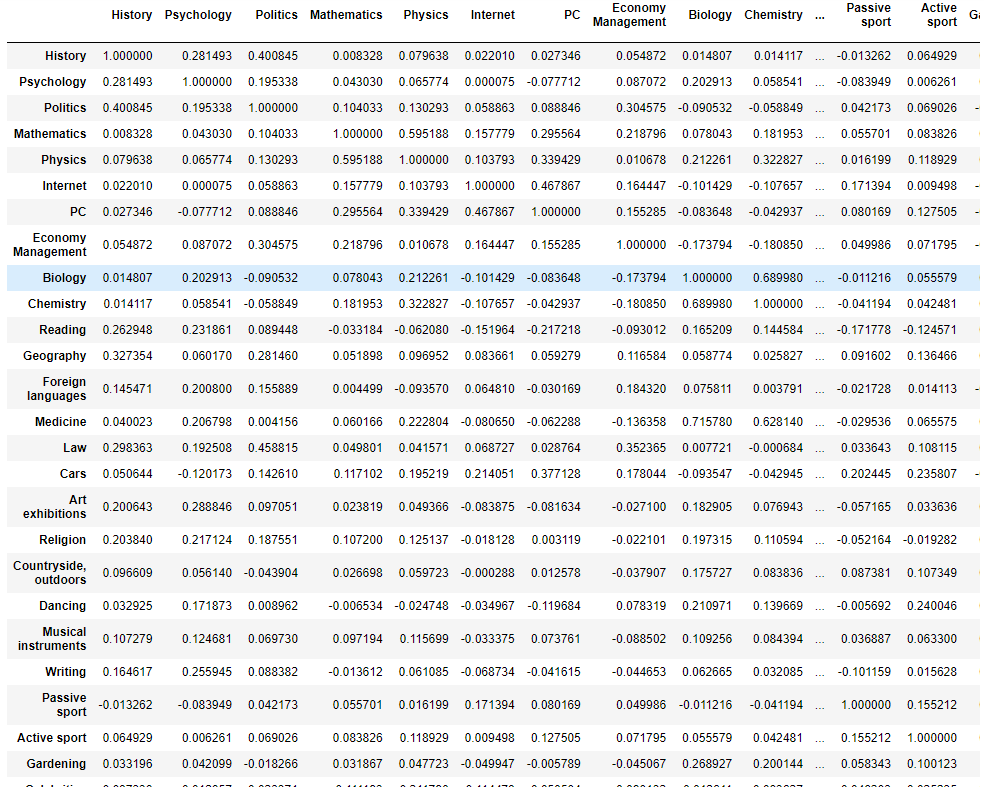
위와 같이 상관관계가 나타내어집니다. 하지만 데이터 시각화가 목적이죠.
여기서 Seaborn의 클러스터맵이라는 함수를 사용해보겠습니다.
sns.clustermap(corr)
위와 같이 전체적인 상관관계(밝은 색깔일수록 양의 상관관계)를 확인할 수 있습니다.
'Data Scientist' 카테고리의 다른 글
| [Data Scientist] 데이터프레임의 Merge(Join) (0) | 2022.09.22 |
|---|---|
| [Data Scientist] 데이터프레임을 GroupBy 해보자 (0) | 2022.09.22 |
| [Data Scientist] Seaborn을 통한 고급 데이터시각화 (0) | 2022.09.21 |
| [Data Scientist] 조건을 만족하는 데이터프레임 (1) | 2022.09.21 |
| [Data Scientist]데이터 처리 라이브러리 - 판다스(Pandas) (1) | 2022.09.21 |
'Data Scientist' Related Articles
more



