Dende
[ML] 머신러닝 분류모델 토이프로젝트 - (3) 탐색적 데이터분석 본문
이전화는 아래를 참조 ^^
[ML] 머신러닝 분류모델 토이프로젝트 - (1) Intro
[ML] 머신러닝 분류모델 토이프로젝트 - (2) 요구사항 분석 및 데이터 준비
이번 장에서는 데이터 분석의 꽃이며 가장 어렵다고 볼 수 있는(지극히 개인적) "탐색적 데이터 분석" 에 대해서 다루겠습니다. 이 과정에서는 초개인화 영화 추천 시스템 개발에 필요한 핵심 데이터를 특정하고, 모델링에서 사용할 데이터를 최적화하는 데 중점을 둘 것입니다.
# 이벤트 정의
이번 분석의 목표는 단순히 인기 있는 영화를 추천하는 것이 아니라, 각 고객에게 맞춤형으로 최적화된 영화 추천을 제공하는 것입니다. 이를 위해, 고객의 행동 패턴과 영화 속성 간의 관계를 깊이 있게 이해하고, 고객이 선호하는 영화 장르를 명확히 식별할 필요가 있습니다.
고객이 보인 행동(예: 구매, 시청, 평가)은 그들의 영화 선호도를 반영하는 중요한 지표입니다. 예를 들어, 고객이 특정 장르의 영화를 자주 구매하거나, 시청 완료 후 긍정적인 평가를 남기면 해당 장르를 선호한다고 볼 수 있습니다. 반면, 시청 기록이 없는 장르이거나, 단순히 탐색만 한 경우에는 해당 장르를 비선호하거나 관심이 없는 장르로 정의할 수 있습니다.
이제, 고객 행동 패턴을 분석하여 고객의 어떤 이벤트(패턴)들이 해당 장르를 선호하는 것으로 판단되는지를 코드와 결과 DataFrame을 통해 확인해보겠습니다.
1. 패키지 및 기본 설정을 합니다.
############################################################################################################
## 1. 패키지 import
############################################################################################################
import pandas as pd
import sqlite3
import os
from datetime import datetime, timedelta
import time
from dateutil.relativedelta import relativedelta
# 사용 예시
from module.logger import log_message
import module.sqlTransaction as sqlT
import importlib
importlib.reload(sqlT)
############################################################################################################
## 2. 초기설정
############################################################################################################
# 경로설정
dir_work = f'c:/Users/user/movie'
dir_func = f'{dir_work}/src/module'
dir_data = f'{dir_work}/data'
# DB연결
conn = sqlite3.connect(f"{dir_data}/pine_movie.db", isolation_level=None)
cur = conn.cursor()
# 함수 호출
# exec(open(f"{dir_func}/sqlTransaction.py" , encoding= 'utf-8').read() )
# exec(open(f"{dir_func}/logger.py" , encoding= 'utf-8').read() )
2. 고객별/영화별로 행동 패턴을 이진화(0 또는 1)하여, 고객이 각 영화에 대해 어떤 행동을 했는지를 테이블화합니다.
※ 테이블 DDL과 적재부분은 이전화를 참고!
# cur.execute(f"""DROP TABLE CUST_ACT""")
cur.execute(
f"""
CREATE TABLE IF NOT EXISTS CUST_ACT AS
SELECT
a01.회원번호
, a01.기준년월
, a01.영화번호
, max(case when a01.행동번호 = 5 then 1 else 0 end) AS 탐색여부
, max(case when a01.행동번호 = 11 then 1 else 0 end) AS 구매여부
, max(case when a01.행동번호 = 4 then 1 else 0 end) AS 시작여부
, max(case when a01.행동번호 = 2 then 1 else 0 end) AS 완료여부
, max(case when a01.행동번호 = 1 then 1 else 0 end) AS 평점여부
FROM (
SELECT
a01.회원번호
, a01.기준년월
, a01.기준년월일
, a01.영화번호
, a01.행동번호
, a01.평점
, a01.판매액
FROM MOVIE_FACT a01
GROUP BY a01.기준년월, a01.회원번호, a01.영화번호, a01.행동번호
) a01
LEFT JOIN movie_fact a02
ON
a01.기준년월 = a02.기준년월
AND a01.회원번호 = a02.회원번호
AND a01.영화번호 = a02.영화번호
GROUP BY a02.기준년월, a02.회원번호, a02.영화번호
"""
)
pd.read_sql(f" select * from CUST_ACT", conn)
행동번호를 기준으로, 고객의 특정 영화에 대한 행동을 확인했습니다. 각 행동번호별로 행동명은 'ACTIVITY' 테이블 참조.
3. 행동 패턴별 분석 및 선호 이벤트 정의
그 다음에는 고객의 영화 소비 행태를 패턴코드로 변환하였습니다. 아래의 표에서는 고객의 행동을 1110이라는 코드로 표현한 예시이며, 이는 구매, 시청 시작, 시청 완료를 했다는 의미입니다.

위 데이터를 활용하여, 회원별, 영화별로 행동 패턴을 집계한 결과, 각 행동 패턴의 비율을 도출할 수 있었습니다.
pd.read_sql(
f"""
SELECT
행동패턴
, count(1) AS 건수
FROM (
SELECT
구매여부 || 시작여부 || 완료여부 || 평점여부 as 행동패턴
FROM CUST_ACT
)
GROUP BY 행동패턴
ORDER BY 행동패턴 DESC
"""
, conn)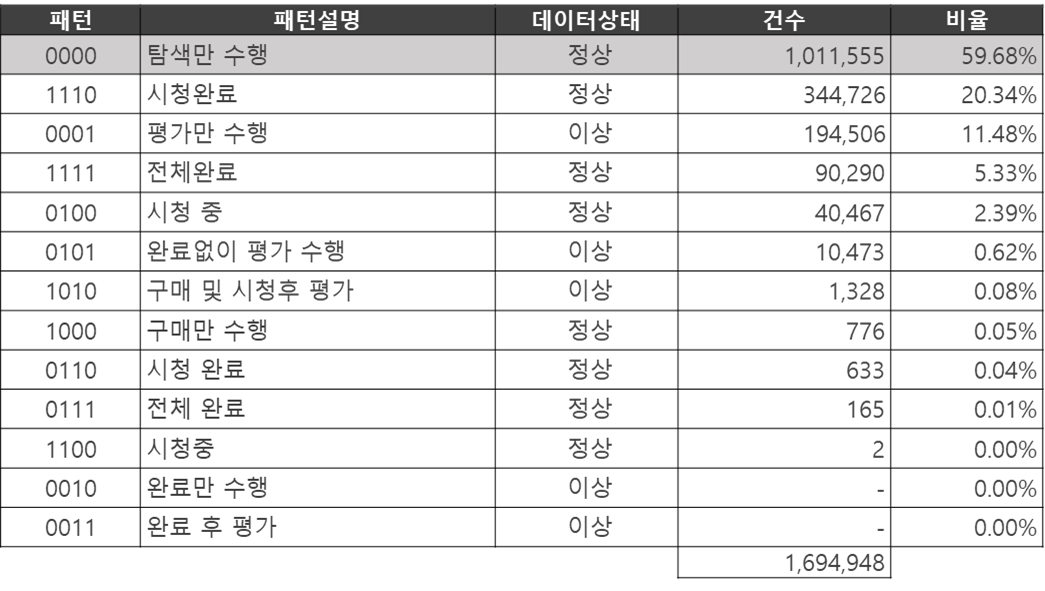
가장 많은 비율을 차지한 패턴은 탐색만 수행한 경우였으며, 그 아래로 시청 완료, 평가만 수행한 경우가 뒤따랐습니다. 이러한 결과는 고객이 많은 영화에 대해 관심을 보이지만, 실제로 구매하거나 평가를 남기는 등의 후속 행동으로 이어지지 않는 경우가 많다는 것을 시사합니다.
그러나 장르에 대한 선호도는 단순히 탐색에 그치는 것이 아니라, 고객이 해당 영화에 대해 더 적극적인 행동을 보였는지를 기준으로 파악해야 한다고 판단하였습니다. 이에 따라, 탐색을 제외한 모든 활동을 단 한 가지라도 수행한 경우, 해당 영화를 선호하는 것으로 가정하였습니다.
다만, 동일한 고객이 같은 장르의 영화를 한 달 동안 여러 번 반복적으로 소비한 경우에는 중복을 방지하기 위해 한 번만 기록하도록 처리하였습니다. 이를 통해 고객의 장르별 영화 선호도를 보다 정확하게 추정할 수 있습니다.
# 분석 대상 장르 정의
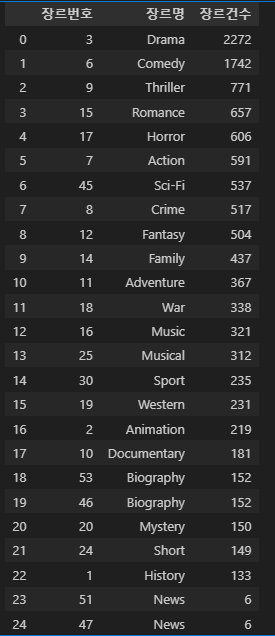
이번 분석에서는 총 23개의 영화 장르를 대상으로 데이터를 검토한 후, 모델 적합성, 이벤트 건수, 매출 통계를 기준으로 장르를 단계적으로 제거하는 방식으로 진행했습니다. 이는 최종적으로 효과적인 마케팅과 매출 증대를 위해, 타겟 장르를 선별하는 과정입니다. 참고로 전체 장르 및 영화건수는 다음과 같았습니다.
######################################################################
### 1-1. 장르별 영화건수
######################################################################
pd.read_sql(
f"""
SELECT
t1.장르번호
, t2.장르명
, COUNT(*) as 장르건수
FROM movie_genre t1
LEFT JOIN genre t2
ON t2.장르번호 = t1.장르번호
GROUP BY t1.장르번호
ORDER BY 장르건수 desc
""" , conn
)
장르 선별 과정
매칭되는 영화 수가 적은 장르
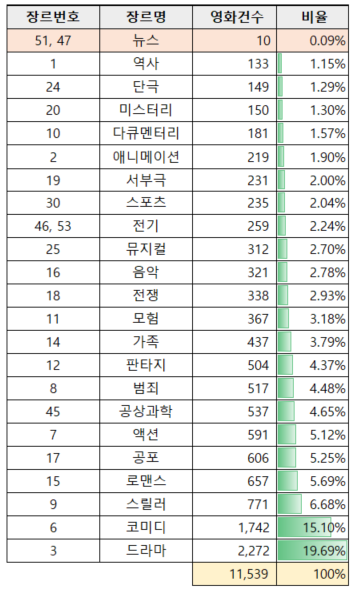
뉴스(10건)는 전체 영화 데이터 중 매칭되는 영화 수가 매우 적었기 때문에 제외되었습니다.
### 1-1. 장르별 영화건수
pd.read_sql(
f"""
SELECT
t1.장르번호
, t2.장르명
, COUNT(*) as 장르건수
FROM movie_genre t1
LEFT JOIN genre t2
ON t2.장르번호 = t1.장르번호
GROUP BY t1.장르번호
ORDER BY 장르건수 desc
""" , conn
)
이벤트 건수가 지나치게 적은 장르
스포츠, 전기, 뮤지컬, 음악, 단편극, 미스터리, 역사, 서부극, 다큐멘터리 등 9개 장르는 이벤트 건수가 5만 건 이하로 매우 적어서 제외되었습니다.
예를 들어, 전기는 5만 건 이하의 이벤트 건수를 기록했고, 서부극과 다큐멘터리도 이와 유사한 패턴을 보여 모델에 적합하지 않다고 판단되었습니다.
######################################################################
### 1-2. 영화 선호 패턴 건수가 적은 장르
######################################################################
pd.read_sql(
f"""
SELECT
기준년월
, SUM(CASE WHEN 장르번호 = 1 THEN 1 ELSE 0 END ) AS 역사
, SUM(CASE WHEN 장르번호 = 2 THEN 1 ELSE 0 END ) AS 애니메이션
, SUM(CASE WHEN 장르번호 = 3 THEN 1 ELSE 0 END ) AS 드라마
, SUM(CASE WHEN 장르번호 = 6 THEN 1 ELSE 0 END ) AS 코미디
, SUM(CASE WHEN 장르번호 = 7 THEN 1 ELSE 0 END ) AS 액션
, SUM(CASE WHEN 장르번호 = 8 THEN 1 ELSE 0 END ) AS 범죄
, SUM(CASE WHEN 장르번호 = 9 THEN 1 ELSE 0 END ) AS 스릴러
, SUM(CASE WHEN 장르번호 = 10 THEN 1 ELSE 0 END ) AS 다큐멘터리
, SUM(CASE WHEN 장르번호 = 11 THEN 1 ELSE 0 END ) AS 모험
, SUM(CASE WHEN 장르번호 = 12 THEN 1 ELSE 0 END ) AS 판타지
, SUM(CASE WHEN 장르번호 = 14 THEN 1 ELSE 0 END ) AS 가족
, SUM(CASE WHEN 장르번호 = 15 THEN 1 ELSE 0 END ) AS 로맨스
, SUM(CASE WHEN 장르번호 = 16 THEN 1 ELSE 0 END ) AS 뮤직
, SUM(CASE WHEN 장르번호 = 17 THEN 1 ELSE 0 END ) AS 공포
, SUM(CASE WHEN 장르번호 = 18 THEN 1 ELSE 0 END ) AS 전쟁
, SUM(CASE WHEN 장르번호 = 19 THEN 1 ELSE 0 END ) AS 서부극
, SUM(CASE WHEN 장르번호 = 20 THEN 1 ELSE 0 END ) AS 미스터리
, SUM(CASE WHEN 장르번호 = 24 THEN 1 ELSE 0 END ) AS 단극
, SUM(CASE WHEN 장르번호 = 25 THEN 1 ELSE 0 END ) AS 뮤지컬
, SUM(CASE WHEN 장르번호 = 30 THEN 1 ELSE 0 END ) AS 스포츠
, SUM(CASE WHEN 장르번호 = 45 THEN 1 ELSE 0 END ) AS 공상과학
, SUM(CASE WHEN 장르번호 = 46
OR 장르번호 = 53 THEN 1 ELSE 0 END ) AS 전기
, SUM(CASE WHEN 장르번호 = 47
OR 장르번호 = 51 THEN 1 ELSE 0 END ) AS 뉴스
FROM (
SELECT
a01.회원번호
, a01.기준년월
, a01.영화번호
, a01.행동패턴
, a02.장르번호
, a03.장르명
FROM (
SELECT
회원번호
, 기준년월
, 영화번호
, 구매여부||시작여부||완료여부||평점여부 AS 행동패턴
FROM CUST_ACT
) a01
LEFT JOIN MOVIE_GENRE a02
ON a01.영화번호 = a02.영화번호
LEFT JOIN GENRE a03
ON a02.장르번호 = a03.장르번호
WHERE a01.행동패턴 <> '0000'
)
GROUP BY 기준년월
"""
, conn
)
여러 장르 패턴에서 중복 등장하는 장르
**드라마(339,503건, 16.67%)**와 **코미디(219,122건, 10.76%)**는 상위 50개 패턴에서 각각 60%와 30% 점유율을 차지하며 과도하게 중복되는 경향을 보여, 장르의 다양성 확보를 위해 모델 대상에서 제외되었습니다.
######################################################################
### 1-3. 복수 장르 보유 영화 추출
######################################################################
df_genre_dup = pd.read_sql(f"""
SELECT
t1.영화번호
, t2.영화명
, t1.장르수
, t1.목록
, case when instr(t1.목록, '3,' ) > 0 then 1 else 0 end as 장르_드라마
, case when instr(t1.목록, '6,' ) > 0 then 1 else 0 end as 장르_코미디
, case when instr(t1.목록, '9,' ) > 0 then 1 else 0 end as 장르_스릴러
, case when instr(t1.목록, '15,') > 0 then 1 else 0 end as 장르_로맨스
, case when instr(t1.목록, '17,') > 0 then 1 else 0 end as 장르_공포
, case when instr(t1.목록, '7,' ) > 0 then 1 else 0 end as 장르_액션
, case when instr(t1.목록, '45,') > 0 then 1 else 0 end as 장르_공상과학
, case when instr(t1.목록, '8,' ) > 0 then 1 else 0 end as 장르_범죄
, case when instr(t1.목록, '12,') > 0 then 1 else 0 end as 장르_판타지
, case when instr(t1.목록, '14,') > 0 then 1 else 0 end as 장르_가족
, case when instr(t1.목록, '11,') > 0 then 1 else 0 end as 장르_모험
, case when instr(t1.목록, '18,') > 0 then 1 else 0 end as 장르_전쟁
, case when instr(t1.목록, '16,') > 0 then 1 else 0 end as 장르_음악
, case when instr(t1.목록, '25,') > 0 then 1 else 0 end as 장르_뮤지컬
, case when instr(t1.목록, '30,') > 0 then 1 else 0 end as 장르_스포츠
, case when instr(t1.목록, '19,') > 0 then 1 else 0 end as 장르_서부극
, case when instr(t1.목록, '2,' ) > 0 then 1 else 0 end as 장르_애니메이션
, case when instr(t1.목록, '10,') > 0 then 1 else 0 end as 장르_다큐멘터리
, case when instr(t1.목록, '53,') > 0 or
instr(t1.목록, '46,') > 0 then 1 else 0 end as 장르_전기
, case when instr(t1.목록, '20,') > 0 then 1 else 0 end as 장르_미스터리
, case when instr(t1.목록, '24,') > 0 then 1 else 0 end as 장르_단극
, case when instr(t1.목록, '1,' ) > 0 then 1 else 0 end as 장르_역사
, case when instr(t1.목록, '51,') > 0 or
instr(t1.목록, '47,') > 0 then 1 else 0 end as 장르_뉴스
FROM (
SELECT
영화번호
, COUNT(장르번호) as 장르수
, GROUP_CONCAT(장르번호) || ',' as 목록
FROM movie_genre
GROUP BY 영화번호
) t1
--------------------------------------------------
-- 영화명 데이터 추출을 위한 조인
--------------------------------------------------
LEFT JOIN movie t2
ON t1.영화번호 = t2.영화번호
--------------------------------------------------
-- 장르수 2개 이상인 영화만 추출
--------------------------------------------------
WHERE t1.장르수 > 1
GROUP BY t1.영화번호
"""
, conn)
df_genre_dup.drop(columns = ['영화번호', '영화명', '장르수', '목록']).sum().to_frame(name = '중복발생건수')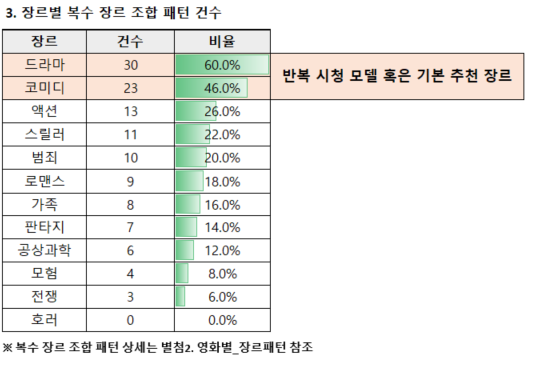
총판매액 및 구매건수가 낮은 장르
애니메이션, 가족, 판타지, 전쟁, 로맨스, 공상과학 등 6개의 장르는 구매건수와 총판매액이 낮았기 때문에 모델 대상으로 적합하지 않다고 판단하여 제외했습니다.
######################################################################
### 1-4. 장르별 매출총액, 구매건수 탐색
######################################################################
pd.read_sql(
f"""
SELECT
t1.장르번호
, t2.장르명
, COUNT(1) AS 구매건수
, sum(t1.판매액) AS 총판매액
FROM movie_fact t1
LEFT JOIN genre t2
ON t2.장르번호 = t1.장르번호
WHERE t1.판매액 is not null
AND t1.장르번호 IN (2, 7, 8, 9, 11, 12, 14, 15, 17, 18, 45) -- 1차 필터링 이후 11개의 장르
GROUP BY
t1.장르번호
, t2.장르명
ORDER BY 총판매액 DESC
"""
, conn)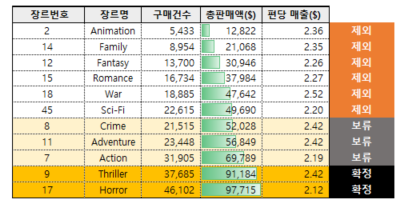
선호 이벤트는 있지만 구매로 이어지지 않은 패턴이 많은 장르
모험은 고객 선호 패턴이 높았으나, 실제 구매로 이어지는 비율이 낮은 장르로 판단되어 제외되었습니다. 이는 무료 영화 비율이 높기 때문으로 분석됩니다.
######################################################################
### 1-5. 판매 실적이 낮은 영화
######################################################################
pd.read_sql(
f"""
SELECT
a02.장르번호
, a03.장르명
, SUM(1) AS 전체건수
, SUM(CASE WHEN 구매여부 = 1 THEN 1 ELSE 0 END ) AS 구매건수
FROM (
SELECT
영화번호
, 구매여부
FROM CUST_ACT
WHERE 구매여부 || 시작여부 || 완료여부 || 평점여부 <> '0000'
) a01
-- 장르번호 매핑
LEFT JOIN MOVIE_GENRE a02
ON a01.영화번호 = a02.영화번호
-- 장르명 매핑
LEFT JOIN GENRE a03
ON a02.장르번호 = a03.장르번호
WHERE a02.장르번호 IN (7, 11, 8) -- 후보군 3개의 장르
GROUP BY
a02.장르번호
, a03.장르명
ORDER BY SUM(CASE WHEN 구매여부 = 1 THEN 1 ELSE 0 END ) DESC
"""
, conn)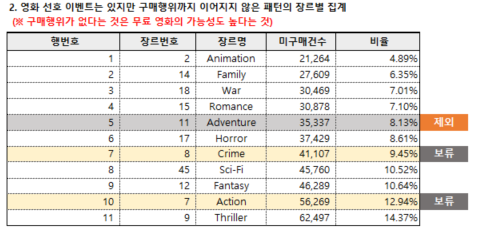
최신 영화 및 블록버스터 보유 개수를 기준으로 필터링
최신 영화 보유 수와 블록버스터 영화 보유 개수 역시 중요한 기준이었습니다. 범죄 장르는 최신 영화나 블록버스터 영화 보유 개수가 적었기 때문에 제외되었습니다.반면, **액션(258개 블록버스터 보유)**과 공포, 스릴러는 최신 영화 및 블록버스터 보유 수가 높아 최종 타겟 장르로 채택되었습니다.
######################################################################
### 1-6. 2차 장르 제외 3번
### - 장르별 최신영화 보유 개수
### - 장르별 블록버스터 보유 개수
### - 장르별 평균 평점 비교
######################################################################
# 장르별 최신영화 보유 개수
df_recent = pd.read_sql(f"""
select
t1.*
, t2.개봉년
, count(1) AS 최신영화개수
from movie_genre t1
left join movie t2
on t1.영화번호 = t2.영화번호
where 장르번호 in (7,8)
and 개봉년 > 2004
and 개봉년 < 2014
group by 장르번호
"""
, conn)
display(df_recent)
# 장르별 블록버스터 영화 보유 개수 집계
df_buster = pd.read_sql(f"""
select
t1.*
, t2.개봉년
, count(1) AS 블록버스터영화개수
from movie_genre t1
left join movie t2
on t1.영화번호 = t2.영화번호
where 장르번호 in (7,8)
and 박스오피스 > 100000000
group by 장르번호
"""
, conn)
display(df_buster)
# 장르별 평점 집계
df_ratings = pd.read_sql(f"""
SELECT
T1.장르번호
, COUNT(1)
, SUM(T2.평점) AS 평점총합
, AVG(T2.평점) AS 평점평균
FROM(
SELECT
a01.회원번호
, a01.기준년월
, a01.영화번호
, a01.행동패턴
, SUBSTR(a01.행동패턴, 4, 1) AS 평점부여여부
, a03.장르번호
, a04.장르명
FROM (
SELECT
회원번호
, 기준년월
, 영화번호
, 구매여부 || 시작여부 || 완료여부 || 평점여부 AS 행동패턴
FROM CUST_ACT
) a01
-- 장르번호 매핑
LEFT JOIN MOVIE_GENRE a03
ON a01.영화번호 = a03.영화번호
-- 장르명 매핑
LEFT JOIN GENRE a04
ON a04.장르번호 = a03.장르번호
WHERE a01.행동패턴 <> '0000'
AND a03.장르번호 IN (7,8)
) T1
LEFT JOIN (
SELECT
기준년월
, 영화번호
, 회원번호
, 평점
FROM MOVIE_FACT
WHERE 평점 IS NOT NULL
) T2
ON
T2.기준년월 = T1.기준년월
AND T2.영화번호 = T1.영화번호
AND T2.회원번호 = T1.회원번호
WHERE T1.평점부여여부 = '1'
AND T1.장르번호 IN (7,8)
GROUP BY T1.장르번호
"""
, conn)
display(df_ratings)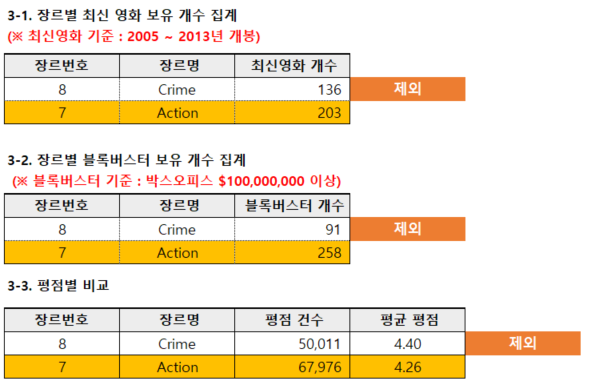
이와 같은 장르 선별 과정을 통해 분석에 적합한 장르만을 남기는 작업을 수행했습니다.
이번 글을 정리하자면,
이벤트 정의:
- 고객이 영화에 대해 보인 행동 패턴을 바탕으로, 단순히 탐색한 경우를 제외하고, 구매, 시작, 완료, 평가 중 하나 이상의 행동을 한 경우, 해당 장르에 대한 선호 이벤트로 정의하였습니다. 이를 통해 고객의 실제 영화 소비를 반영하고, 선호도를 추정할 수 있었습니다.
최종 타겟 장르:
- 액션: 최신 영화 보유 개수와 블록버스터 비율이 높고, 매출 기여도가 큰 장르
- 공포: 고객 선호도와 더불어 매출 기여도도 높아 마케팅 타겟으로 적합.
- 스릴러: 높은 매출 기여도와 선호 패턴을 보이며, 블록버스터 영화 보유 비중이 큰 장르
최종적으로 이 장르들을 중심으로 한 맞춤형 추천 시스템이 구축될 예정입니다. 이를 통해, 단순히 인기 영화만 추천하는 것이 아니라, 고객의 개별적인 선호도를 반영한 초개인화 추천 시스템을 구축하여 고객 만족도와 매출을 함께 증가시키는 것을 목표로 하고 있습니다.
다음장에서는 본격적인 모델링 단계인 마트 생성 입니다!
'Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 분류모델 토이프로젝트 - (4) 분석마트 (4) | 2024.09.13 |
|---|---|
| [ML] 머신러닝 분류모델 토이프로젝트 - (2) 요구사항 분석 및 데이터 준비 (2) | 2024.09.03 |
| [ML] 머신러닝 분류모델 토이프로젝트 - (1) Intro (1) | 2024.09.03 |


