Dende
[Data Scientist] 데이터클리닝 본문
1. 완결성
pandas에서는 결치값에 대해서 Nan(Not a Number)식으로 표출됩니다.
하지만 예측되지 못한 Null의 존재는 항상 데이터의 완결성을 헤치는 주원인이 됩니다.
Null을 어떻게 다루느냐가 데이터 엔지니어링의 핵심이 되는 것이죠.
pandas에서 Null을 표적수사하는 함수는 여럿 있습니다.
우선, isnull() 함수부터 사용해보겠습니다.
다음과 같은 데이터가 있습니다.

df.isnull()을 수행하면, 모든 데이터는 본인들이 Null인가 아닌가 여부에 따른 True False를 출력합니다.

df.isnull().sum()연도 0
야구 0
축구 0
배구 3
남자농구 0
여자농구 0
dtype: int64isnull()함수에 sum() 함수를 호출하면 각 컬럼에 대한 Null이 몇 개 존재하는지 확인하실 수 있습니다.
Null표적수사 후 우리들은 Null을 어떤 식으로 처리할 것이냐 하는 고민에 빠지게 됩니다.
우선 간단하게 없애는 방법이 있겠죠. 컬럼이 되었든 레코드가 되었든 삭제를 시도해봅시다.
df.dropna()dropna() 함수를 사용하면 Null값이 존재했던 row는 전부 삭제됩니다.

df.dropna(axis='columns')dropna 함수의 axis 파라미터에 columns를 넣어주면 레코드가 아닌 해당 컬럼 자체가 사라지게됩니다.

그런데 행이든 열이든 데이터가 완전히 사라지는 것을 원하지 않을 수도 있죠.
그럴 땐 SQL의 NVL함수 같이 Null값을 지정된 값으로 채워주는 fillna 함수가 있습니다.
df.fillna(0)모든 Null값에 0을 넣겠다는 것입니다.

하지만 보통 Null값에는 해당 컬럼에 대한 평균이 되었든 중간값이 되었든 예측 가능한 범위의 값이 들어가는게 일반적이겠죠.
그럴 경우에는 df.mean() 혹은 df.median() 함수를 활용해주시면 됩니다.
df.fillna(df.mean())
2. 유일성

다음과 같은 데이터가 있습니다.
이 데이터프레임에는 특정 로우와 특정 열이 중복된 값을 가지고 있습니다.
먼저 인덱스 중복을 표적수사해봅시다.
df.index.value_counts()07월 31일 2
08월 11일 1
07월 26일 1
07월 14일 1
07월 15일 1
07월 16일 1
07월 17일 1
07월 18일 1
07월 19일 1
07월 20일 1
07월 21일 1
07월 22일 1
07월 23일 1
07월 24일 1
07월 25일 1
07월 27일 1
08월 10일 1
07월 28일 1
07월 29일 1
07월 30일 1
08월 01일 1
08월 02일 1
08월 03일 1
08월 04일 1
08월 05일 1
08월 06일 1
08월 07일 1
08월 08일 1
08월 09일 1
07월 13일 17월 31일 값이 두개인 것을 확인해볼 수 있습니다.
그렇다면 없애줘야겠죠. 중복된 로우를 없애는 것은 drop_duplicate 함수입니다.
df.drop_duplicates(inplace=True)
중복된 행이 사라진 것을 확인할 수 있습니다.
다음으로 중복된 컬럼을 삭제해봅시다.
데이터프레임을 .T를 활용해 행과 열을 전환시켜 duplicated를 적용시키면 중복된 열을 제거할 수 있습니다.
df = df.T.drop_duplicates()
df
성공적으로 '강원1' 컬럼이 삭제된 것을 확인하실 수 있습니다.
3. 정확성
이상치 데이터(Outlier)는 모델의 성능을 떨어트리는 불필요한 요소이기 때문에 꼭 제거해주어야 합니다.
Outlier의 확인은 1차적으로 EDA 과정에서 그래프를 통해 발견할 수 있지만
어느 시점부터는 '어디까지가 이상치 데이터이다.'라고 판단하는 기준을 반드시 가져야합니다.
여러가지 방법들 중 IQR(Inter Quantile Range) 방식을 토대로 진행해보겠습니다.

다음과 같은 영화 메타데이터가 있습니다.
우리는 위 데이터를 통해 '예산'과 '평점'의 관계를 파악하고 싶습니다.
우선 산점도를 통해 그 분포를 확인해보겠습니다.
df.plot(kind='scatter', x='budget', y='imdb_score')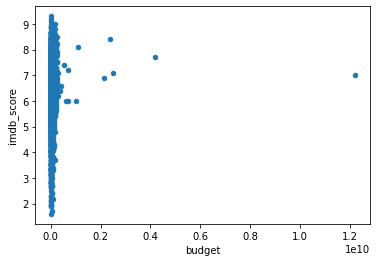
확인 결과, 아주 큰 예산을 쓴 몇몇 영화 때문에 산점도 그래프로 상관 관계를 파악함에 있어 문제가 많아보입니다.
IQR 기준으로 아웃라이어를 제거해보겠습니다.
기준 : 예산을 기준으로 75% 지점에서 5 IQR 만큼 더한 것보다 큰 예산의 영화는 제거
q1 = df['budget'].quantile(0.25)6000000.0df['budget'].quantile(0.75)45000000.0
먼저, 예산을 기준으로 75% 지점은 600000.0 , 25% 지점은 45000000.0이 나왔습니다.
75% 지점에서 5 IQR 만큼 더한 것을 얻는 조건은 다음과 같습니다.
q1 = df['budget'].quantile(0.25)
q3 = df['budget'].quantile(0.75)
iqr = q3 - q1
condition = (df['budget'] > q3 + 5 * iqr)
75% 지점은 q3으로 선언되었고 q3 + 5 IQR 보다 큰 값은 아웃라이어로 취급하겠습니다.
df[condition]
아웃라이어 7개가 도출되었습니다.
아웃라이어를 제외하고 산점도를 다시 그려보겠습니다.
df.drop(df[condition].index, inplace=True)
df.plot(kind='scatter', x='budget', y='imdb_score')
아웃라이어가 빠지면서 산점도가 좀 더 보기 쉬운 형태로 바뀌었습니다.
'Data Scientist' 카테고리의 다른 글
| [Data Scientist] 데이터 다운로드 받기 (0) | 2022.09.23 |
|---|---|
| [Data Scientist] 특정 인덱스만 받아오기 (0) | 2022.09.23 |
| [Data Scientist] 데이터프레임의 Merge(Join) (0) | 2022.09.22 |
| [Data Scientist] 데이터프레임을 GroupBy 해보자 (0) | 2022.09.22 |
| [Data Scientist] 상관관계 분석 (1) | 2022.09.21 |


